GEO Best Practices: Prompt Volume Shouldn’t Drive Your Strategy
Most advice on generative engine optimization best practices starts in the same place: find the prompts people are using with AI tools, track which ones give your brand visibility, and build content around the highest-volume queries.
The problem? That data is largely estimated.
Generative engine optimization (GEO) is still new enough that the infrastructure to measure it accurately doesn’t exist yet. Think of how GEO differs from SEO: the mature, reliable signals you’ve come to expect from tools like Semrush or Ahrefs took years to develop. GEO measurement isn’t there yet. What platforms call “prompt volume” is modeled, estimated, and often directionally wrong.
This post breaks down why prompt volume is an unreliable foundation for your GEO strategy and what the best-performing teams do instead.
Key Takeaways
- “Prompt volume” is a modeled estimate, not actual user data, making it an unreliable starting point for GEO decisions.
- AI behavior is inconsistent; people phrase prompts differently and models return varied answers, making patterns hard to trust at small scale.
- AI “rankings” are unstable; studies show results change constantly, so tracking position the way you track SEO doesn’t translate.
- Most data sources, whether panels or APIs, are biased or don’t reflect real user behavior in AI tools.
- Citation drift is high, meaning sources and visibility shift month to month even for identical prompts.
- GEO tools are still early and directional, not definitive; treat them accordingly.
- Clustering prompts around your ICP’s actual language outperforms chasing vendor-curated query lists.
- A consistent monitoring schedule matters more than obsessing over any single data point.
Why Prompt Volume Misleads Your GEO Strategy
1. LLMs Don’t Have Search Volume: It’s Estimated, Not Measured
The most fundamental problem is that there is no true “AI search volume” the way Google exposes search query data. LLMs don’t publish query frequency or search volume equivalents. Their responses vary, sometimes subtly and sometimes dramatically, even for identical queries, due to probabilistic decoding and prompt context. They also depend on hidden contextual features like user history, session state, and embeddings that are opaque to external observers. What platforms sell as “prompt volume” is a modeled estimate, not a direct measurement.
2. LLM Responses Are Non-Deterministic by Nature
Traditional keyword volume works because millions of people type the same phrase into Google and those queries are logged. AI interactions are fundamentally different. Search behavior in traditional SEO is repetitive, with millions of identical phrases driving stable volume metrics. LLM interactions are conversational and variable. People rephrase questions differently, often within a single session, making pattern recognition harder with small datasets.
This non-determinism is baked into how LLMs work. They produce text using probabilistic methods, selecting words based on their likelihood rather than following a set pattern. The same prompt can produce different responses, which makes consistent and accurate conclusions difficult to draw.
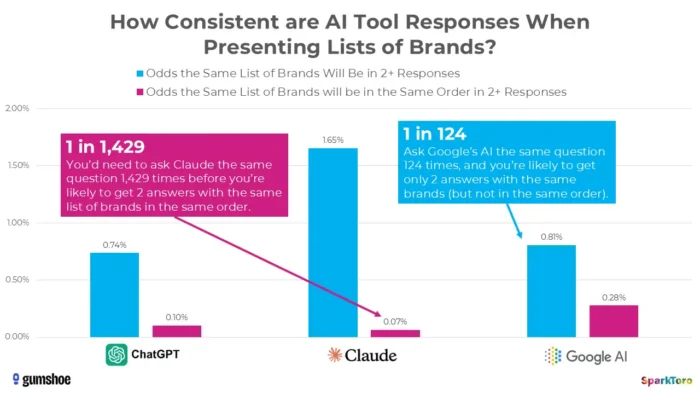
3. SparkToro’s Research Shows Rankings Are Essentially Random
The most compelling evidence comes from a landmark January 2026 study by Rand Fishkin and Gumshoe.ai. They tested 2,961 prompts across 600 volunteers on ChatGPT, Claude, and Google AI. The finding: there is less than a one in 100 chance of getting the same brand list in any two responses, and less than one in 1,000 chance of the same list in the same order. As Fishkin bluntly concluded, any tool that gives a “ranking position in AI” is essentially making it up.
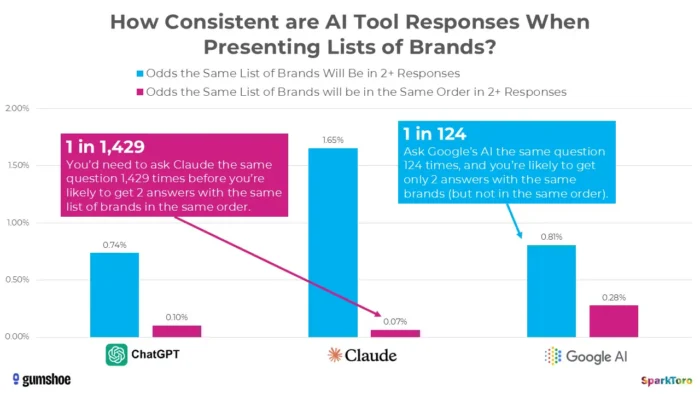
Research from SparkToro highlights significant variability in AI-generated brand recommendations even when identical prompts are used, suggesting that point-in-time AI visibility measurements may reflect volatility rather than durable performance signals.
4. Panel-Based Methodology Has Inherent Bias Problems
Platforms like Profound rely on opt-in consumer panels to source their prompt data. Profound licenses conversations from multiple, double opt-in consumer panels of real answer engine users, with scale in the hundreds of millions of prompts per month, and applies advanced probabilistic modeling to extrapolate frequency, intent, and sentiment across broader populations.
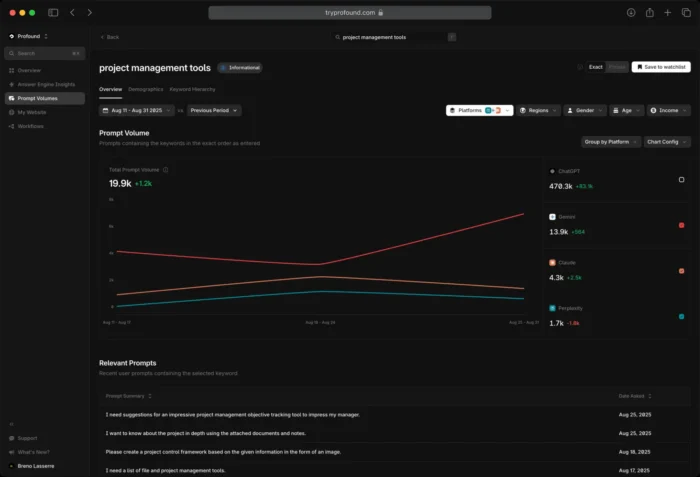
While this sounds robust, the opt-in nature of these panels means the sample may skew toward more tech-savvy, engaged users, not a representative cross-section of how the general population actually prompts AI tools.
5. API Queries Don’t Reflect Real Human Behavior
Many tools query AI models via API to simulate user prompts, but this introduces another gap. Most AI tracking tools rely on API calls rather than mimicking human interface usage, and early research suggests API results may differ from interface results, though the magnitude and implications of these differences require further investigation. The API-focused nature of querying data also means that results are not aligned with what humans actually search for.
6. Citation Drift Is Massive and Unpredictable
Even if you ignore everything above, the month-to-month stability of AI citations is shockingly low. A study by Profound measured citation drift month over month and observed very large changes in cited domains even for identical prompts. Google AI Overviews and ChatGPT showed monthly variations of dozens of percentage points.
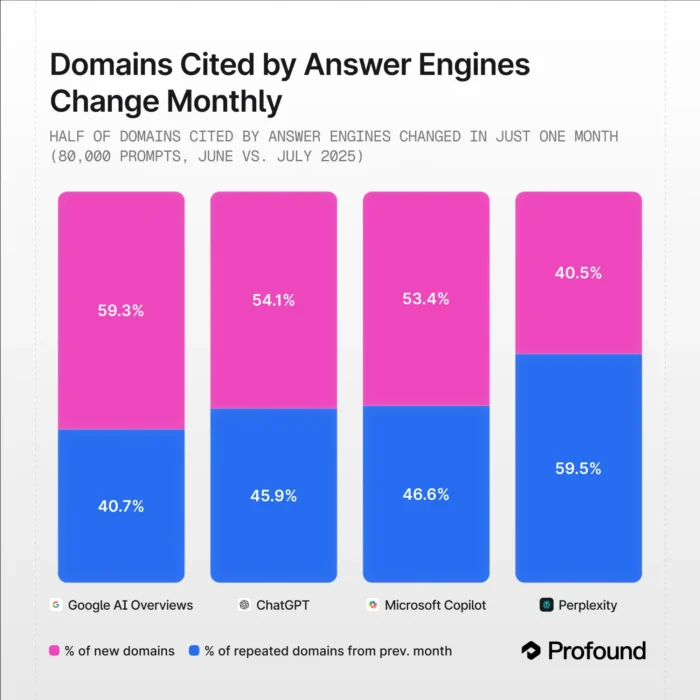
This means the “volume” attached to any given prompt today may look completely different next month, making it an unreliable foundation for content investment decisions.
7. We’re in a Pre-Semrush Era: The Tools Don’t Yet Have the Infrastructure
We’re still in a pre-Semrush/Moz/Ahrefs era for LLMs. Nobody has complete visibility into LLM impact on their business today. Be wary of any vendor or consultant promising complete visibility, because that simply isn’t possible yet. Current tracking data should be treated as directional and useful for decisions, but not definitive.
Generative Engine Optimization Best Practices: What to Do Instead
Prompt volume is one signal among many, and right now it’s one of the weaker ones. Here are the generative engine optimization best practices that actually hold up.
Start With Your ICP, Not a Dashboard
Rather than letting estimated prompt volume dictate your GEO content priorities, start with what you actually know about your audience. The strongest signal you have is your Ideal Customer Profile. What problems are your best customers hiring you to solve? What language do they use to describe those problems? Those pain points, not a vendor’s modeled prompt estimates, should be the foundation of what you optimize for in AI answers.
Source: The Smarketers
If you’ve done solid ICP work, you’re already sitting on better data than any prompt volume tool can give you.
Go Where Your Audience Already Talks
Layer in real audience research by going where your audience speaks openly and honestly. Reddit threads, niche forums, LinkedIn comments, Slack communities, and review sites like G2 and Trustpilot are places where people ask unfiltered questions in their own words. That’s exactly the kind of natural language that maps closely to how someone would prompt an AI tool. If your ICP is repeatedly asking “how do I justify the ROI of X to my CFO” in a subreddit, that’s a far more reliable content brief than a prompt volume number attached to a vendor-curated query.
Mine Your Own Customer Conversations
Customer-facing teams are one of the most underused sources of GEO intelligence. Sales call recordings, support tickets, customer interviews, and onboarding conversations are rich with the exact phrasing real buyers use when they’re stuck, skeptical, or evaluating options. That language belongs in your content and ultimately in AI answers. If your sales team hears the same objection every week, there’s a good chance someone is asking an AI the same question.
Cluster and Organize Prompts Around Your Audience’s Language
Once you have raw input from your ICP work, forums, and customer conversations, the next step is structuring it. Rather than treating each potential prompt as an isolated target, group them by intent and theme.
Prompt clustering around similar topics or pain points helps you see patterns in how your audience thinks about a problem, not just how they phrase a single question. A cluster around “how to measure GEO success” might include prompts about metrics, reporting, stakeholder communication, and benchmarking. Each of those deserves content, and the overlap between them tells you what your core narrative should be.
This is a meaningful shift from keyword research logic. When you’re thinking about GEO versus AEO, the organizing principle stays the same: topical authority around the problems your audience is trying to solve. Prompt organization by intent and theme is what lets you build that authority systematically.
Use Prompt Volume Tools for What They’re Actually Good At
None of this means abandoning platforms like Profound or Writesonic entirely. Used correctly, they’re genuinely useful for directional awareness: spotting topic gaps, monitoring whether your brand is appearing in the right conversations, and tracking share of voice against competitors over time.
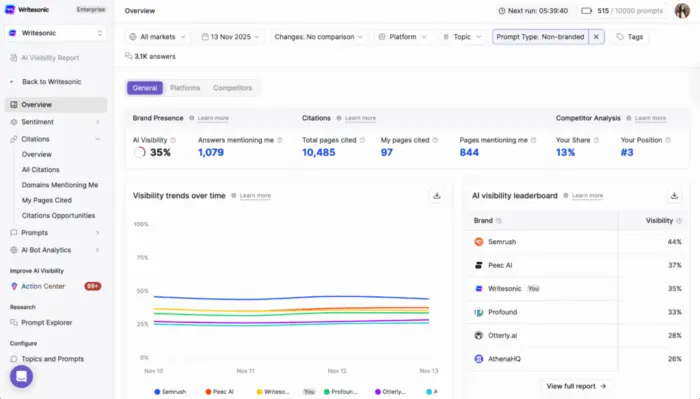
The mistake is using them as a keyword volume substitute and letting their estimates drive what you create. Let your ICP, audience research, and real customer conversations tell you what to optimize for. Then use prompt volume data to pressure-test and monitor, not to decide.
Build a Monitoring Schedule That Actually Works
Given how much citation drift exists in AI outputs, monitoring needs to be structured and consistent rather than reactive. Checking your brand’s AI visibility once a quarter isn’t enough. A monthly monitoring schedule for your core prompt clusters gives you a reasonable baseline for spotting meaningful shifts without over-indexing on noise.
Here’s how to approach it practically. Set up a defined list of 20 to 30 prompts that reflect your ICP’s most common questions. Run them on a set cadence, at least monthly, across the platforms your audience uses most, such as ChatGPT, Perplexity, and Google AI Overviews. Track whether your brand, your content, or your competitors are appearing. Note changes, but don’t overreact to single-month swings given how much variation exists. What you’re watching for is directional trends over three to six months, not week-to-week positions.
This is what separates teams with a real AI search optimization strategy from those reacting to dashboard alerts. Monitoring informs; it doesn’t decide.
The Bottom Line
Prompt volume tries to approximate demand that you may already have direct access to. The brands that win in AI search aren’t the ones chasing the most-tracked prompts. They’re the ones who understand their audience deeply enough to show up in the answers their customers are actually looking for.